
Konzept Häufigkeitsanalyse

Die Häufigkeitsanalyse ist eine der Methoden, die statistische Eigenschaften von verschlüsselten Texten ausnutzen, um Rückschlüsse auf die unverschlüsselte Nachricht zu ziehen.
In jeder Sprache kommen die einzelnen Buchstaben in einem ausreichend langen Text in einer für die Sprache charakteristischen Häufigkeit vor. Im Deutschen ist der am häufigsten vorkommende Buchstabe das E (etwa 17%), gefolgt von N (ca. 10%), I und R (je ca. 8%). Ersetzt man also in einer verschlüsselten Nachricht das am häufigsten vorkommende Zeichen mit E, und die nächsthäufigsten mit N, I und R, dann hat man gute Chance, schon ca. die Hälfte des Textes übersetzt zu haben.
Häufigkeitsverteilung der Buchstaben im Deutschen
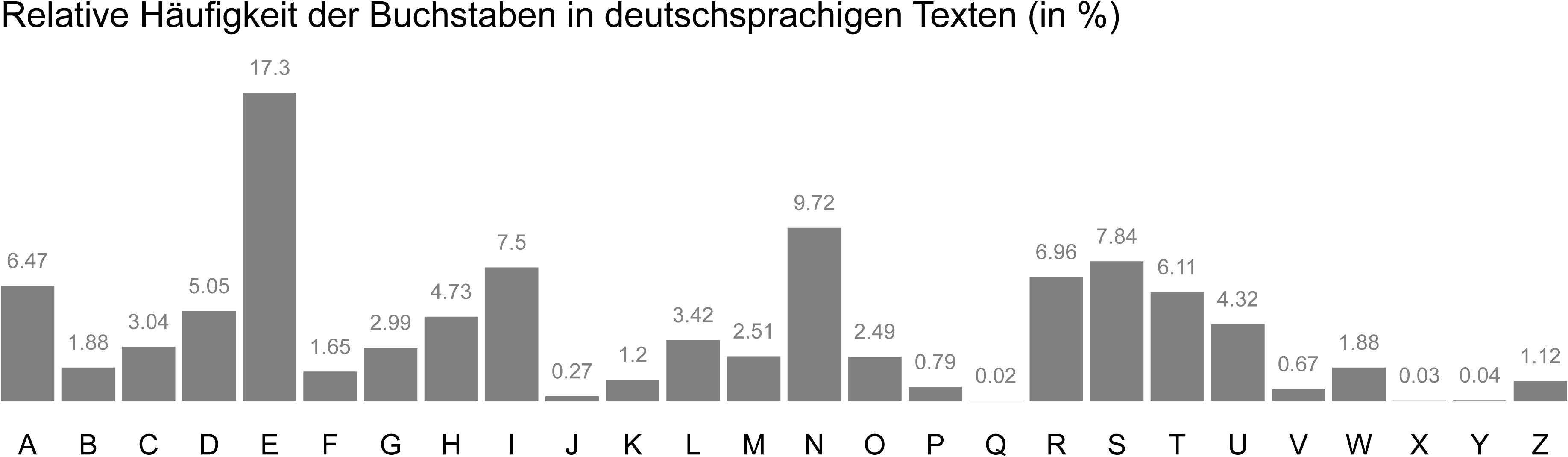
Quelle: Oinf
Natürlich gibt es noch weitere ähnliche Ansätze:
- Der erste Buchstabe in drei-Zeichen-Worten ist wahrscheinlich ein D (der, die, das, den,…).
- Ein Zeichen, das fast nur in Begleitung eines bestimmten anderen Zeichens vorkommt, ist ziemlich sicher ein C (gefolgt von H).
- Ein Zeichen, das nur in Begleitung eines bestimmten anderen Zeichens vorkommt, ist sehr sicher ein Q (gefolgt von U).
- Das E ist am Wortende sehr häufig gefolgt von N (üblichster Plural), innerhalb von Wörtern oft in Kombination mit I (ei, ie).
- Nur wenige Buchstaben können doppelt vorkommen, im Deutschen verdoppelt man zumeist N, M oder T.
- Vokale und Konsonanten können zumeist aufgrund ihrer Verteilung in Wörtern voneinander unterschieden werden.