
BigData
Big Data meint die riesigen Datenmengen, die von Internetriesen und Geheimdiensten gesammelt und verwertbar gemacht werden.
MATERIALIEN
Das Internet und die ihm zugrunde liegende Digitalisierung haben es sehr einfach gemacht, immer grössere Datenmengen zu sammeln und auszuwerten. Nicht immer geschieht das zum Vorteil der Konsumenten.
Viele Daten
Das Schlagwort Big Data bedeutet zunächst einmal: Viele Daten. Um wie viele Daten genau es geht, ist naturgemäss schwer anzugeben – allein schon weil die Datenmenge so rasant steigt. So gab es im Jahr 2011 schätzungsweise 1.8 Zettabytes an digitalen Daten – würde man diese Daten auf DVDs brennen, ergäbe sich ein Stapel, der von der Erde bis zum Mond und wieder zurück reicht (http://deacademic.com/dic.nsf/dewiki/305107). Zudem ist das Wachstum exponentiell; Experten gehen davon aus, dass sich die Menge verfügbarer digitaler Daten etwa alle ein bis zwei Jahre verdoppelt – so sind Anfang 2018 schätzungsweise etwa 12 Zettabytes im Internet verfügbar (eine aktuelle Schätzung kann man sich unter http://live-counter.com/wie-gross-ist-das-internet/ anschauen).
Weil inzwischen so vieles digital gemessen und erfasst wird, weil wir so viele Bilder und Videos produzieren und teilen, weil alle beständig digital miteinander kommunizieren, weil die Unzahl vernetzter Geräte im «Internet der Dinge» noch eine weitere Datenflut automatisch erzeugt und weil die nötige Hardware (für Rechenkapazität, Speicherplatz, Vernetzung) inzwischen günstig genug ist, sammeln sich unvorstellbar grosse Datenberge an.
Das explosionsartige Wachstum des Internets bedeutet, dass insbesondere eine Handvoll internationaler Grosskonzerne (allen voran Google, Facebook, Amazon, IBM, General Electric, Apple, Microsoft) sowie manche Geheimdienste wahrhaft gigantische Datenmengen angehäuft haben, bei denen es besonders um uns, die Benutzer, geht. Auch in manchen Wissenschaftsgebieten fallen enorme Datenmengen an, z.B. in der Astronomie, in der Teilchenphysik, bei Wetter- und Klimasimulationen oder bei der Genom-Sequenzierung. Aber eigentlich sammelt inzwischen jede grössere Firma oder Organisation oder Behörde eine Menge an Daten, die als Big Data gelten kann.
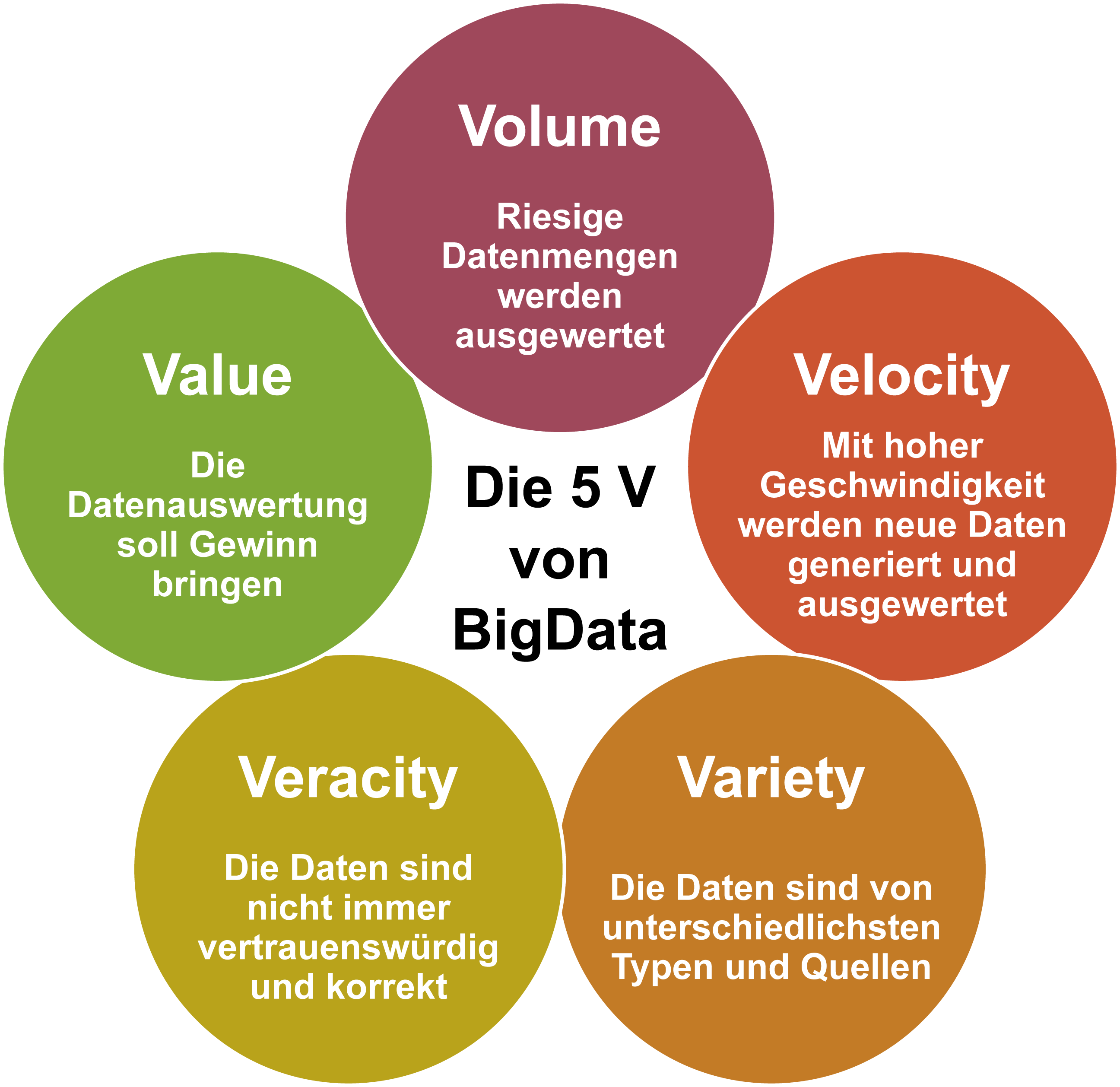
Die fünf Vs
Big Data ist in vielerlei Hinsicht ein Kumulationspunkt fast aller bisher besprochener Konzepte: Eine immer grösser werdende Menge (Volume) an Informationen wird digitalisiert und damit als universell verarbeitbare Daten gespeichert. Aufgrund der umfassenden Vernetzung können Daten in Echtzeit (Velocity) zusammengeführt und in Datenbanken verfügbar gemacht werden, wobei insbesondere Metadaten eine wichtige Rolle bei der Strukturierung (Veracity) und Verknüpfung (Variety) von Datensätzen aus verschiedenen Quellen spielen. Egal um welche Arten von Daten es sich handelt, die Sammler der Daten der ersten vier Vs stellen sicher, dass etwas von Wert (V Nummer fünf: Value) für sie herausspringt.
Big Data
Der aus dem englischen Sprachraum stammende Begriff Big Data (von englisch big ‚groß’ und data ‚Daten’) bezeichnet Datenmengen, welche beispielsweise zu groß, zu komplex, zu schnelllebig oder zu schwach strukturiert sind, um sie mit manuellen und herkömmlichen Methoden der Datenverarbeitung auszuwerten. Im deutschsprachigen Raum ist der traditionellere Begriff Massendaten gebräuchlich.
«Big Data» wird häufig als Sammelbegriff für digitale Technologien verwendet, die in technischer Hinsicht für eine neue Ära digitaler Kommunikation und Verarbeitung und in sozialer Hinsicht für einen gesellschaftlichen Umbruch verantwortlich gemacht werden.
In der Definition von Big Data bezieht sich das «Big» auf die drei Dimensionen volume (Umfang, Datenvolumen), velocity (Geschwindigkeit, mit der die Datenmengen generiert und transferiert werden) sowie variety (Bandbreite der Datentypen und -quellen). Erweitert wird diese Definition um die zwei V value und validity, welche für einen unternehmerischen Mehrwert und die Sicherstellung der Datenqualität stehen.
Quelle: Wikipedia, Big Data (16.06.2019)
Analogie
Big Data ist ein rein digitales Konzept, eine Analogie aus der realen Welt kann keinen Sinn machen.
Immer rechenkräftigere Computersysteme können auf dieser Basis per Algorithmus zunehmend genauere Vorhersagen generieren – z.B. über fehlende oder auch zukünftige Informationen – woraus sich auf verschiedenste Weisen Wert (Value) schöpfen lässt.
Big Data als Profit
Der Wert bzw. das intendierte Ziel von Big-Data-Anwendungen ist so verschieden wie offensichtlich, die Spanne reicht von der Maximierung von Kundenzufriedenheit oder Profit über die Optimierung von Produkten oder Abläufen bis hin zu zuverlässigeren Prognosen von Wetter, Verkehr oder Krankheitsverläufen – um nur einige zu nennen. Sehr viel schwieriger ist es zu beurteilen, inwiefern das intendierte Ziel auch tatsächlich erreicht wird und ob der Wert die möglichen negativen Konsequenzen (für wen?) aufwiegt – als illustratives Beispiel mag hier der massive Einsatz von Big Data durch die NSA und andere Geheimdienste dienen, die jeweils mit der Gewährleistung der nationalen Sicherheit begründet werden, aber gleichzeitig die Privatsphäre aller kompromittieren. Auch am Beispiel der Personalisierung sieht man, dass BigData-Anwendungen u.U. gerade dann die gravierendsten gesellschaftlichen Auswirkungen haben können, wenn sie ihr Ziel (hier die Vorhersage der Interessen des Benutzers) erreichen.
Im Einzelnen ist keine der Zutaten zum Big-Data-Rezept neu, doch in der Kombination ergibt sich seit etwa Anfang der 2010er Jahre eine neue Qualität. Das hängt insbesondere mit zwei Faktoren zusammen: Zum einen wird zunehmend offensichtlicher, in welchem Ausmass einzelne Akteure (vor allem Internetgiganten und Geheimdienste) Benutzerdaten sammeln, zusammenführen und oft dauerhaft speichern. Zum anderen bewirken entscheidende Fortschritte auf dem Gebiet des Maschinellen Lernens, dass bestimmte Arten der Auswertung selbst grösster Datenmengen inzwischen möglich sind, oftmals sogar in Echtzeit. Beides führt dazu, dass alle Besitzer grösserer Datenmengen zunehmend über den Einsatz von Big-Data-Techniken nachdenken.

Risiken und gesellschaftliche Auswirkungen von Big Data
Es ist kaum zu bezweifeln, dass die Datenmengen in Zukunft noch gigantischer und die Algorithmen zu deren Auswertung – insbesondere in selbstlernenden Systemen – noch effizienter und verbreiteter sein werden. Wir stehen erst am Beginn des Big-Data-Zeitalters. Wie die meisten technischen Umwälzungen wird das positive und negative Auswirkungen nach sich ziehen. In diesen beiden Talks findet sich eine eher optimistische Sichtweise und eine, in der die Risiken betont werden:
Fazit
Zumindest die recht verbreitete Ansicht, dass viele Daten in Kombination mit Maschinenlernen automatisch alles besser machen wird, scheint doch sehr naiv.

Im Folgenden wird auf eine Auswahl problematischer Aspekte eingegangen, die mit Big Data Anwendungen verbunden sind. Diese Probleme gibt es mit jeder Art von Schlussfolgerungen von spezifischen Informationen aus grossen Datenmengen; die genaue Methode (z.B. rein statistische Verfahren, Maschinelles Lernen, Netzwerkanalysen) ist ziemlich irrelevant. Um die Problematiken verständlich zu erklären, werden sie hier jeweils auf ein bestimmtes, nicht ganz hypothesisches Beispiel bezogen, nämlich die Verbrechensprävention.
Predictive Policing mit Big Data
Um Verbrechen besser verhindern zu können, möchte die Polizei auf der Basis verschiedener Personen- und Metadaten ableiten, wer kriminell ist oder werden wird. Dafür wird ein entsprechendes System entwickelt, das aus den Daten der letzten zehn Jahre mit 95%-iger Wahrscheinlichkeit vorhersagen kann, welche Personen für ein Verbrechen verurteilt werden. Diese Informationen sollen nun verwendet werden, um potentielle Straftäter frühzeitig zu erkennen und Gegenmassnahmen einzuleiten.
Fehlerhafte Ergebnisse
Wie wir alle von Wetterprognosen gewohnt sind, ist jede Vorhersage mit einer gewissen Unschärfe versehen. Auch wenn die Wahrscheinlichkeit für eine korrekte Vorhersage oder Klassifikation sehr hoch ist, bleiben immer einige Einzelfälle übrig, in denen das Ergebnis – der hohen Wahrscheinlichkeit zum Trotz – eben doch falsch ist. Das kann aus mehreren Gründen zum Problem werden.
Der offensichtlichste ist der, dass mir der generelle Erfolg einer Methode herzlich egal sein kann, wenn genau ich von einem solcher Einzelfall betroffen bin, in dem das Ergebnis falsch ist. Erschwerend kommt hinzu, dass ich kaum Möglichkeiten habe, um mich gegen ein solches Ergebnis zu wehren oder auch nur zu beweisen, dass die Vorhersage in meinem Fall fehlerhaft war.
Weniger offensichtlich ist, dass es verschiedene Arten von statistischen Fehlern gibt, was den Umgang mit der verbleibenden Fehlerwahrscheinlichkeit auf der Ebene des Einzelfalls nicht unbedingt intuitiv macht (Statistiker wissen das seit langem).
Fehlerhafte Ergebnisse am Beispiel Predictive Policing
Nehmen wir an: Die Identifikation von Kriminellen funktioniert zu 95% zuverlässig. Franz ist einer derjenigen, die als kriminell eingestuft wurden – stimmt das jetzt zu 95%?
Die Antwort: Nein, Denn das ist eben das Problem mit der Anwendung von statistischen Fehlern auf den Einzelfall: Aufgrund der Testzuverlässigkeit sind 5% der Ergebnisse falsch. Aber in welche Richtung? 5% der Verbrecher werden nicht erkannt («false negatives») während 5% der Unbescholtenen fälschlicherweise als kriminell eingestuft werden («false positives»). Die Frage ist also, ob Franz wirklich kriminell oder ein «false positive» ist.
Zur Beantwortung dieser Frage muss man sich die Zahlenverhältnisse klar machen. Nehmen wir an, überwacht werden 10’000 Personen, von denen 100 (1%) tatsächlich kriminell sind. 95 der 100 Verbrecher werden also korrekt erkannt («true positive») – Franz könnte einer davon sein. Andererseits gibt es auch 9900 Normalbürger, von denen 5% (also 495 Personen) ein «false positive» erhalten – bezogen auf den Einzelfall ist es also ziemlich unwahrscheinlich (95 zu 495, also nur rund 16%), dass Franz tatsächlich ein Verbrecher ist.
Gesellschaftliche Dynamik
Die Validität der Big Data Analyse bezieht sich notwendigerweise zu einem grossen Teil auf Daten aus der Vergangenheit – wenn sich Zusammenhänge ändern, verliert die Analyse an Gültigkeit. Erschwerend kommt hinzu, dass die auf der Analyse beruhenden Massnahmen oftmals den Nebeneffekt haben, dass gerade dadurch besagte Zusammenhänge verändert werden.
Gesellschaftliche Dynamik am Beispiel Predictive Policing
Die 95% Zuverlässigkeit im Beispiel ergeben sich aus der Erkennungsleistung des Systems mit Daten aus den vergangenen 10 Jahren. Natürlich sind Big-Data-Analysen immer auf Generalisierung ausgerichtet, man kann also schon davon ausgehen, dass es auch mit neuen Beispielen gut funktionieren wird – deswegen validiert man das System ja auch (hoffentlich) mit einem Testset und nicht den Trainingsbeispielen. Allerdings funktioniert die Generalisierung notwendigerweise nicht mehr, wenn sich die dahinterstehenden (bei Maschinellem Lernen oft impliziten) Zusammenhänge ändern. Dummerweise ist das speziell bei auf Menschen bezogene Daten oft der Fall – vielleicht sind die «Kriminalitätsmuster» heute ganz andere als vor zehn Jahren (besonders wenn die Betroffenen ihre Daten- bzw. Verhaltensmuster absichtlich versuchen zu ändern, weil auch sie – zumindest grob – verstehen, wie das System funktioniert). Das würde bedeuten, dass die Erkennungsrate in Wirklichkeit viel weniger gut ist, als angenommen.
Dazu kommt, dass die zukünftige Datenlage durch die Auswirkungen des Systems entschieden verändert wird: All die fälschlicherweise aus dem Verkehr Gezogenen haben ja gar keine Möglichkeit mehr zu zeigen, dass sie eben nicht kriminell geworden wären. Oder sie werden eben gerade dadurch kriminalisiert, dass man sie von vorneherein als Verbrecher behandelt.
Mass des Erfolgs
Wie beurteilen wir, ob eine Big-Data-Anwendung und die damit zusammenhängenden Massnahmen die Situation verbessert haben? Oft ist es schon gar nicht so einfach, die positiven Auswirkungen zu messen. In jedem Fall jedoch ist ein Mass für den Erfolg zweifelhaft, wenn es nicht in angemessener Weise die negativen Auswirkungen berücksichtigt.
Mass des Erfolgs am Beispiel Predictive Policing
In unserem Beispiel können wir 95% der Kriminellen aus dem Verkehr ziehen, ggf. sogar bevor sie ein Verbrechen verübt haben, und verringern damit sicher die Wahrscheinlichkeit neuer Straftaten – das geht aber zulasten von 5% der Normalbevölkerung («false positives»). Es handelt sich um eine moralische Frage: Darf man 495 unbescholtene Bürger ins Gefängnis stecken, wenn dadurch auch 95 Verbrecher verschwinden? Oder braucht es ein besseres Verhältnis – z.B. eine Erkennungsrate von 99%? Wer entscheidet, ab wann das Verhältnis gut genug ist? Geht es überhaupt um das Verhältnis? …
Um es auf die Spitze zu treiben: Egal wie wir entscheiden, wer aus dem Verkehr gezogen wird (selbst durch Auslosen), es werden auch Verbrecher darunter sein und die Straftaten werden zurückgehen. Um dies zu maximieren, gäbe es ein ganz einfaches Mittel: Wenn einfach alle eingesperrt werden, gibt es garantiert kein Verbrechen mehr. Daraus folgt: Der Rückgang der Kriminalitätsrate ist ein sehr zweifelhaftes Mass für den Erfolg eines solchen Systems. Was aber wäre ein gutes Mass?
Transparenz
Selbst für die Entwickler von Big Data Anwendungen ist es sehr schwer, in der Praxis oft unmöglich (insbesondere bei Maschine Learning-Ansätzen) nachzuvollziehen, wie genau ein bestimmtes Ergebnis zustande kam. Aus diesem Grund lassen sich individuelle Fehlurteile kaum nachweisen oder korrigieren.
Transparenz am Beispiel Predictive Policing
Die Zutaten und Funktionsweise des Kriminalitätserkennungssystems werden kaum veröffentlicht werden, weil die «Bad Boys» ja sonst die Möglichkeit hätten, das System gezielt zu manipulieren. Gleichzeitig verhindert diese Logik, dass (ggf. fälschlicherweise) Verdächtigte sich gegen den Verdacht wehren können.
Verantwortlichkeit
Zumindest ein Rest an Fehlerwahrscheinlichkeit ist also unvermeidbar. Selbst wenn es einem Betroffenen gelingt, den Fehler in seinem Einzelfall nachzuweisen – wer genau kann für diesen Fehler und seine auf der persönlichen Eben u.U. gravierenden Konsequenzen verantwortlich gemacht werden?
Verantwortlichkeit am Beispiel Autonomes Fahren
Dieses Problem lässt sich besser am Beispiel selbstfahrender Autos illustrieren. Selbst wenn ein solches Fahrzeug im Schnitt wesentlich sicherer unterwegs sein sollte als ein vom Menschen gesteuertes, werden sich Unfälle nie gänzlich vermeiden lassen. Wer also ist schuld an einem solchen Unfall, wer zahlt den Opfern ggf. Schadenersatz?
Noch mehr zugespitzt: Im Strassenverkehr gibt es Situationen, in denen ein Fahrzeuglenker einen Unfall nicht vermeiden kann – aber ggf. kann er noch entscheiden, ob eher die Insassen zu Schaden kommen (z.B. ausweichen und gegen einen Baum fahren) oder andere (z.B. Passanten überfahren). Das ist ein moralisches Dilemma, in dem keine der Optionen richtig ist. Bei der Programmierung/dem Training eines selbstfahrenden Systems muss aber eine Präferenz festgelegt werden. Wer verantwortet diese Entscheidung? (s. https://www.ted.com/talks/iyad_rahwan_what_moral_decisions_should_driverless_cars_make)
Privatsphäre
Allein das Prinzip von Big Data ist nur sehr schwer mit datenschutzrechtlichen Grundprinzipien in Einklang zu bringen. Darauf weist der eidgenössische Datenschutzbeauftragte eindrücklich hin:
Nachfolgend werden weitere wesentliche datenschutzrechtliche Aspekte von Big Data aufgeführt:
- Die technologischen Möglichkeiten stellen eine Herausforderung an das datenschutzrechtliche Transparenzerfordernis: Jede Person hat das Recht zu wissen, wer welche Daten über sie zu welchem Zweck bearbeitet. Bei Big Data ist die Datenbearbeitung und die Verknüpfung von Daten aus unterschiedlichen Quellen sehr unübersichtlich und für die betroffenen Personen kaum nachvollziehbar. Deshalb sind die Big-Data-Anwender bezüglich Transparenz und Information der betroffenen Personen besonders gefordert.
- Personenbezogenes Big Data erfordert die Einwilligung der betroffenen Personen. Dabei muss der Zweck der Big-Data-Verfahren für die betroffenen Personen bereits bei der Datenbeschaffung klar und eindeutig erkennbar sein. Dies widerspricht jedoch dem Prinzip von Big Data, wo Daten auf Vorrat gesammelt werden, um einem beliebigen Zweck in der Zukunft zu dienen. Eine offene, allgemeine Zweckumschreibung bei der Information über die Datenbearbeitung hat zur Folge, dass die Einwilligung in die geplante Datenbearbeitung nicht rechtsgültig ist.
- Eine weitere Schwierigkeit stellt die Anforderung der Datenrichtigkeit dar: Bei Big Data werden Algorithmen eingesetzt, die in selbständiger, automatisierter Weise grosse Datenbestände u.a. auf Zusammenhänge hin analysieren. Mit den Analyseverfahren werden neue personenbezogene Informationsinhalte geschaffen, die nicht als falsch oder richtig beurteilt werden können, sondern Wahrscheinlichkeiten oder Interpretationen darstellen.
(https://www.edoeb.admin.ch/edoeb/de/home/datenschutz/Internet_und_Computer/onlinedienste/erlaeuterungen-zu-big-data/erlaeuterung-zu-big-data.html, abgerufen am 19.02.2018)
Privatsphäre am Beispiel Predictive Policing
Es scheint evident, dass das vorgeschlagene Kriminalitätserkennungssystem schwerwiegende Eingriffe in die Persönlichkeitsrechte aller überwachten Personen nach sich zieht – was nur bei einem «überwiegenden öffentlichen Interesse» zulässig sein könnte. Sehen Sie das hier gegeben?
Mehr noch: Stellen Sie sich vor, was man sonst noch alles aus den zugrundeliegenden Daten ableiten könnte. Wenn ein solches System erst eingeführt ist – was genau steht einer fast beliebigen Erweiterung entgegen?
Um diesen Punkt mit einer leicht positiven Note zu beenden: Inzwischen ist auch die Politik auf die potentiellen Probleme von ungezügelten Big Data-Anwendungen aufmerksam geworden. Am 25. Mai 2018 trat in Europa die Datenschutz-Grundverordnung (DSGVO) in Kraft, die u.a. bei der Auswertung von Big Data eine Datenschutz-Folgeabschätzung vorschreibt. Seit September 2023 gilt auch in der Schweiz ein neues Datenschutzgesetz (DSG), das weitestgehend mit der europäischen Regelung übereinstimmt und sogar das Problem des „Profiling“ benennt, also die Möglichkeit der Ableitung von persönlichen Informationen aus grossen Mengen an sich unbedenklicher (Meta-)Daten.
Aufgabe
AlgorithmWatch ist eine gemeinnützige Organisation mit dem Ziel, Prozesse algorithmischer Entscheidungsfindung zu betrachten und einzuordnen, die eine gesellschaftliche Relevanz haben – die also entweder menschliche Entscheidungen vorhersagen oder vorbestimmen, oder Entscheidungen automatisiert treffen.
Mission Statement von Algorithmwatch.org
Seit 2020 gibt es die Schweizer Dependance Algorithmwatch/CH sowie eine schweizspezifische Version des Automating-Society-Report, in dem Sie sich über die aktuelle Verbreitung von BigData-Systemen im öffentlichen Leben eines Landes informieren können.